Operating System Concepts 책(이하 공룡책)을 깊이있게 완독하는 스터디를 진행하고 있는데, 이 중 9장 메인 메모리의 계층적 페이징에서 단계적으로 일어나는 계산에 대해 질문이 있었다. 나는 페이지의 비트에 -2 혹은 -3 하는 것이 매우 당연하다 생각했었는데, 막상 설명하려니 단계적으로 정확히 설명할 수 없었다. 이 부분을 좀 더 명확하게 설명할 필요가 있어 글을 작성하기로 했다.
문제 정의
계층적 페이징을 적용하지 않았을 때는 페이지의 오프셋을 제외한 모든 상위 비트가 페이지 테이블을 표현하는데 사용되어야 한다. 하지만 이를 계층적으로 나눌 수 있는데, 어떤 이유로 각 계층별 비트 수가 결정되는지 알아보자.
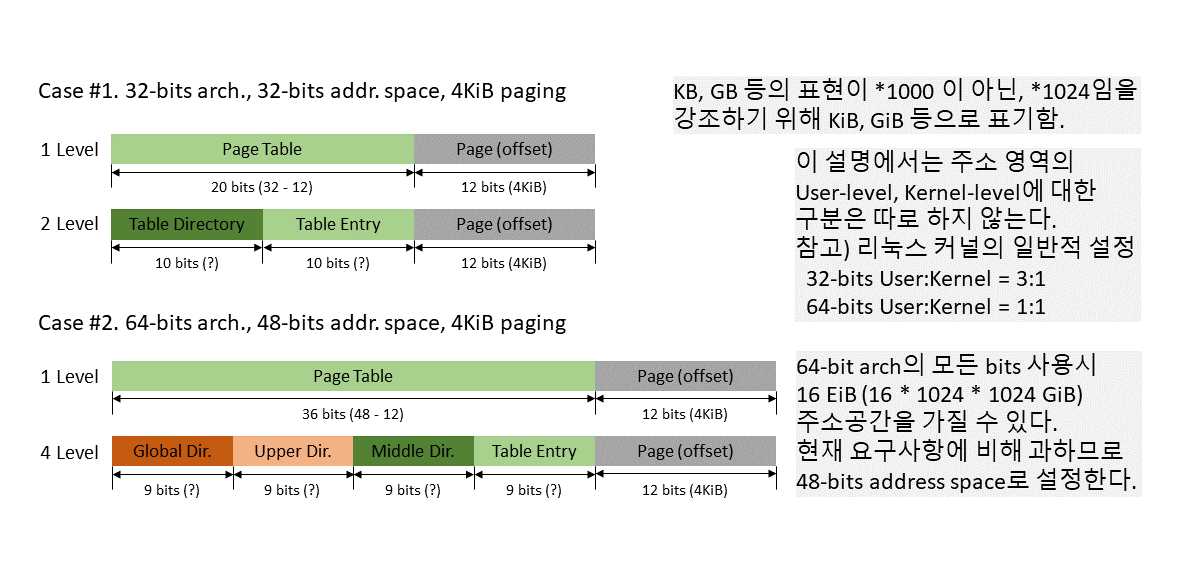
본 글에서는 실제 자주 사용되는 페이징 구조를 기준으로 한다. 먼저 32-bits 환경에서의 계산을 먼저 하고, 숫자 차이인 64-bits 환경에도 적용하면서 일반화 해 보도록 하겠다. 참고로 현재 64-bits 환경의 경우 그림에도 설명했듯 주소 공간을 모두 활용하지 않는다.
사전 지식
참고로 이 설명에서는 요구 페이징(Demand Paging) 개념을 기반으로 계층적 페이징의 필요성을 설득하고 있으므로, 해당 개념에 대해 먼저 간단하게 설명하겠다. (공룡책의 경우 9장이 아닌 10장에서 상세히 설명하므로 순서대로 읽다 보면 아직 요구 페이징을 잘 모를 수도 있다 가정한다.)
요구 페이징
책에서는 메모리의 외부 단편화 등의 문제를 해결하기 위한 방법으로 메모리를 일정한 크기로 구분하여 관리하는 페이징 개념을 제안했다. 또한 가상 주소 개념을 적용함으로서 다른 프로세스의 주소 영역 침범 문제 등을 해결하고자 했다.
이에 따라 각 프로세스는 모두 개별적인 주소 공간을 갖게 되었고, 굳이 프로그램의 크기에 따라 주소 공간의 크기를 가변적으로 할당할 필요도 없게 되었다. 여기에서 더 생각해보면, 각 프로세스는 자신에게 할당받은 주소 공간을 완전히 활용하지 못 할 가능성이 높다. 대표적으로 메모리 영역에서 스택과 힙 영역은 런타임에 크기가 변한다.
즉, 한 프로세스에게 4GB의 주소 공간을 할당해도 실행 상황에 따라 100MB 이하로 쓸 수도 있고, 3GB를 쓸 수도 있다는 것이다. 이런 점을 고려했을 때, 각 프로세스에게 주소 공간만큼 물리 메모리를 할당할 필요가 없다는 것을 알 수 있다. 게다가 실제 사용해보면 대부분이 주소공간을 완전 활용하지 않는다는 것도 알게되었다.
이 외에도 여러 이유가 존재할 수 있으나, 요구 페이징을 설명하는 글이 아니므로 생략하도록 하겠다.
32-bits, 4KiB paging
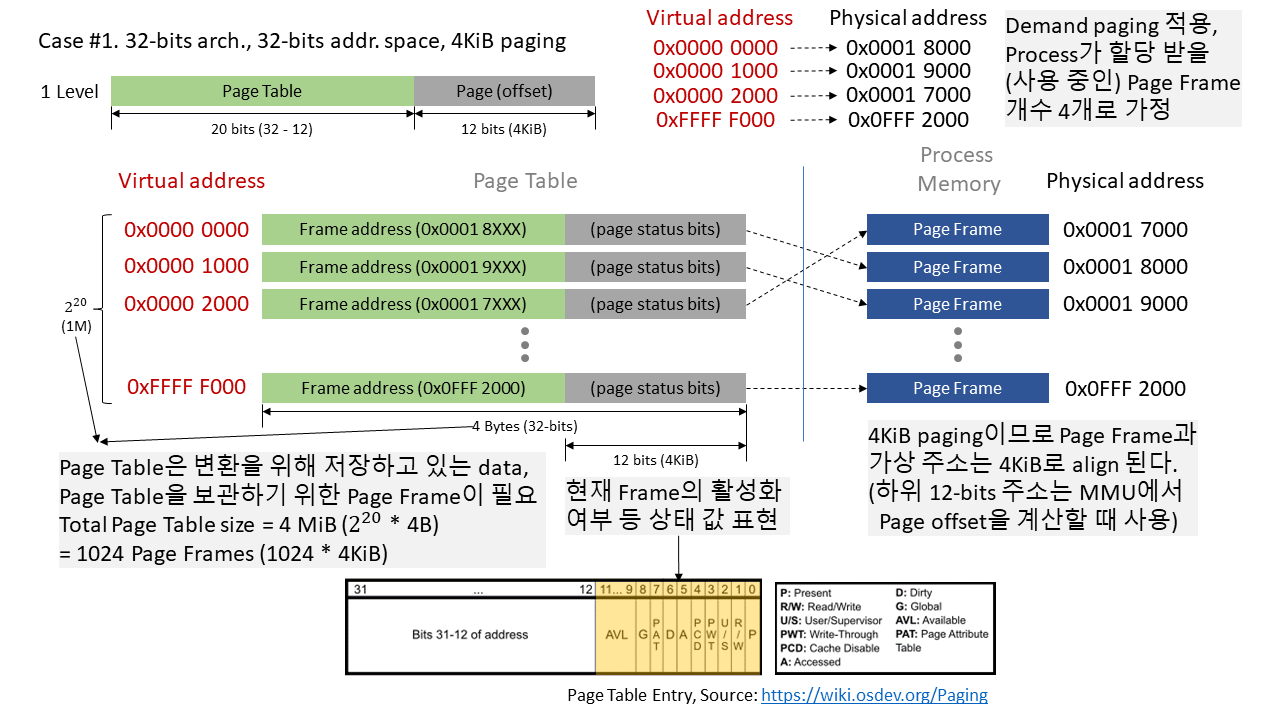
페이징 개념 자체를 학습하느라 놓쳤을 지 모르겠지만, 페이지 테이블은 일종의 메타데이터다. 그리고 이 메타데이터는 다른 어딘가에 보관되어야 사용할 수 있다. (당연히 메모리 관리를 담당하는 커널에서 보관한다.) 여기에 추가적으로 각 페이지 프레임의 속성을 나타내기 위해 개별적으로 메타데이터를 사용하지 않고, 페이징으로 인해 정렬된 하위 비트들을 활용한다. (실제 사용 시, 이 하위 비트들을 비트 연산자로 제거하고 사용한다.)
그림에도 나와있듯, 4KiB 페이징의 경우, 상위 20 비트로 각 페이지 프레임을 나타내고 있으며, 한 페이지 프레임을 표현하기 위해 4바이트(32비트)가 필요하므로, 페이지 테이블의 예상 크기는 4MiB다. 당연히 이 페이지 테이블도 페이지 프레임 단위로 보관될 것이다. 현재 페이지 테이블 크기를 각 페이지 프레임 크기로 나눠보면, 페이지 테이블 표현에만 1024개가 필요함을 알 수 있다. 현재 가정하는 상황에서 페이지 프레임을 4개 사용하는 것에 비해 메타데이터의 크기가 과도하게 크다.
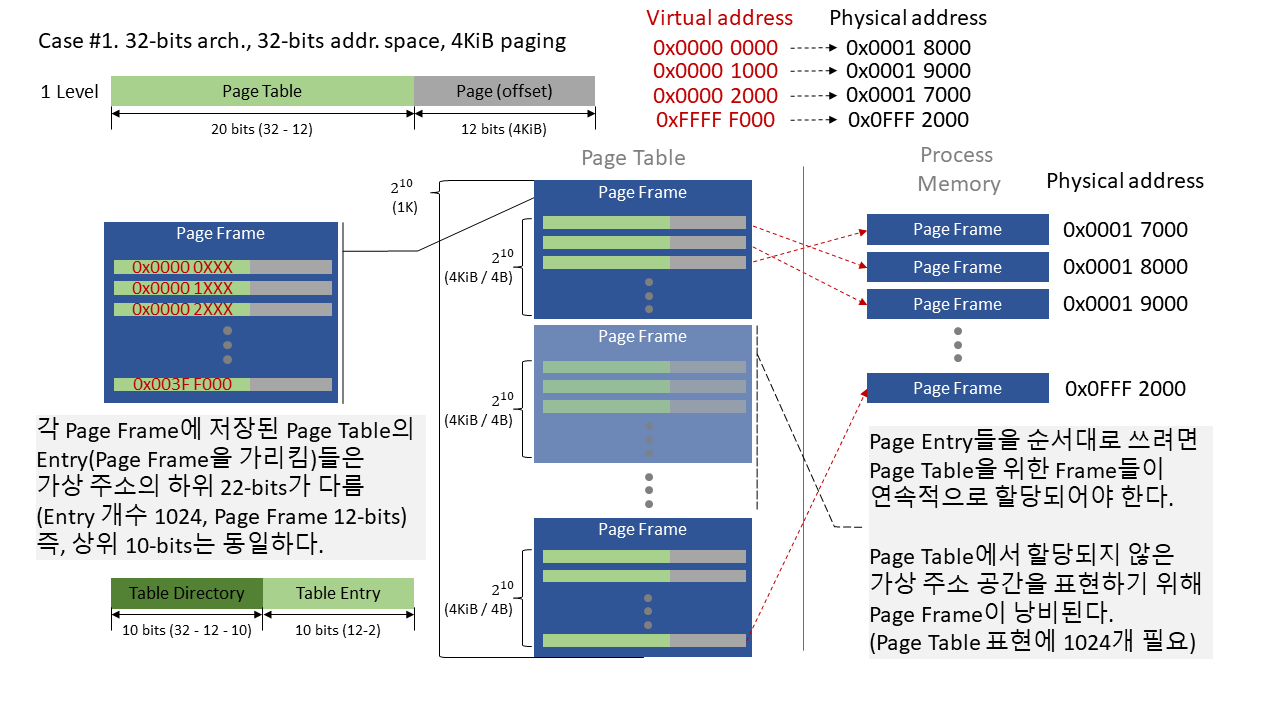
게다가 또 다른 문제가 있다. 페이지 테이블에서는 원하는 주소를 바로 찾기 위해 주소 값들을 저장하고 있는데(이렇게 페이지 프레임을 가리키는 주소를 페이지 테이블 엔트리라 한다.) 이 페이지 테이블을 실제 표현하는 페이지 프레임들은 연속적으로 할당되어야 한다. 1단계 페이징을 적용했을 때, 가상 주소로부터 물리 주소를 구하는 과정을 코드로 표현하면 아래와 같다. (실제 코드는 아니지만 대략 아래와 같은 형식으로 작성된다.)
#define ADDR_BITS 32 // 32-bits address space
#define PAGE_SHIFT 12 // 4KiB page frame
#define SIZE_ADDR_SPACE (1 << ADDR_BITS) // address space
#define SIZE_PF (1 << PAGE_SHIFT) // page frame size
#define P_ATTR_MASK ((1 << PAGE_SHIFT) - 1) // page attribute mask
// page entries must be placed in page frame (resource allocation view)
struct {
void* entry[SIZE_PF / sizeof(void*)];
} pt_frames[SIZE_ADDR_SPACE / SIZE_PF];
// Pointer for page table (abstracted page table view)
void* page_tbl = &pt_frames[0].entry[0];
void* get_page_frame_addr(void *virt_addr)
{
// get index by upper bits of page
int idx = virt_addr >> PAGE_SHIFT;
// entry of physical address is page_tbl[idx]
void* phy_entry = page_tbl[idx];
// Unmask page entry's attribute
return (void*)((int)phy_entry & ~P_ATTR_MASK);
}
void* get_physical_addr(void* virt_addr)
{
// get offset address of page
void* offset = (void*)((int)virt_addr & P_ATTR_MASK);
// get physical page frame address
void* phy_frame = get_page_frame_addr(virt_addr);
return (void*)((int)phy_frame | (int)offset);
}
위 코드에서 보듯, 가상주소에서 물리주소로 변환하는(get_physical_addr()), 가상주소를 통해 물리 페이지 프레임의 주소를 얻는(get_page_frame_addr()) 과정은 오프셋 주소 상위 비트를(virt_addr >> PAGE_SHIFT) 배열의 인덱스처럼 사용하여(page_tbl[idx]) 접근한다. 이 페이지 테이블은 모든 프레임이 연속해야만 (pt_frames[]) 정확한 위치에 인덱싱 할 수 있다.
위에서 설명한 내용을 요약하자면 1단계 페이지 테이블을 그대로 적용한다면 아래와 같은 문제가 있다.
- 페이지 테이블은 실제 물리 주소 공간에 연속적으로 할당되어야 한다.
- 요구 페이징 시, 실제 사용하는 페이지 프레임에 비해 페이지 테이블의 용량이 너무 크다.
페이지 테이블 용량에 대한 문제는 앞의 산수에서 확인되었지만, 페이지 테이블의 공간 연속 할당 문제로 인해 의미 없는 페이지 엔트리들도 표현해야 한다는 점에서 당위성이 생긴다.
그렇다면 현재 1단계 페이징을 할 때, 페이지 테이블의 각 프레임의 속성을 확인해보자. 각 엔트리들이 가리키는 가상 주소들은 연속적이므로, 이를 비트 표현 상의 차이로 확인해보면 상위 10 비트는 언제나 동일한 것을 알 수 있다. 한 페이지에 저장 가능한 엔트리의 개수는 1024개이므로 (4KiB / 4B) 가상 주소 엔트리의 하위 10 비트만 바뀌는 것을 알 수 있다. 이 점을 착안하여, 2단계 페이징을 적용하게 된다.
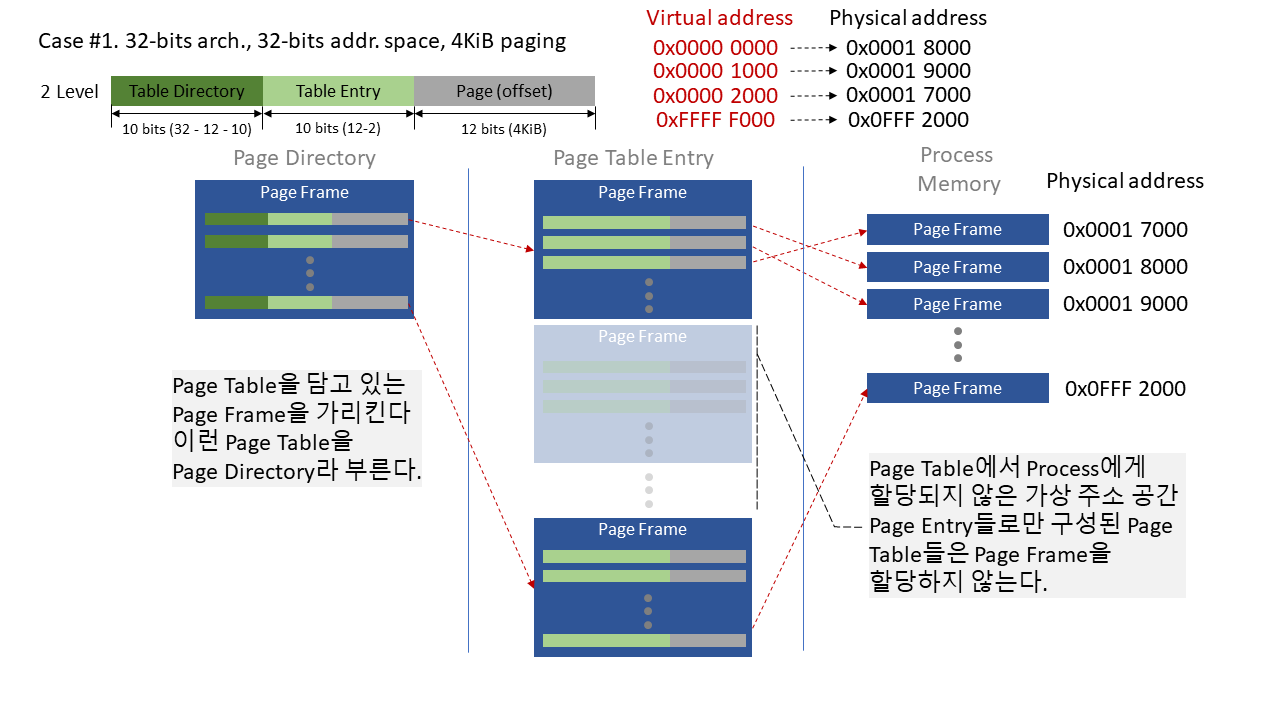
위 그림과 같이, 상위 10비트의 차이를 나타내는 새로운 페이지 테이블을 생성했다. 이 새로운 페이지 테이블은 가상 주소의 상위 10 비트의 주소에 대한 계산만 하고있다. 이렇게 2단계 페이징을 적용함으로서 아까 있던 문제를 어떻게 해결할 수 있는지 알아보자.
- 페이지 테이블은 실제 물리 주소 공간에 연속적으로 할당되어야 한다.
페이지 테이블이 할당된 페이지 프레임을 가리키는 새로운 테이블이 생겼다.
엔트리 계산이 두번 이뤄진다. (최상위 -> 하위 테이블 페이지 프레임, 하위 테이블 -> 실제 페이지 프레임)
페이지 테이블의 물리 주소 할당이 연속적이지 않아도 된다. - 요구 페이징 시, 실제 사용하는 페이지 프레임에 비해 페이지 테이블의 용량이 너무 크다.
만약 1단계 페이징에서 현재 페이지 테이블의 프레임이 실제 페이지 프레임을 하나도 가리키지 않는다면, 생략할 수 있다.
즉, 불필요한 페이지 테이블을 생략할 수 있다.
물론 페이지 테이블이 2단계가 됨으로서 변환 연산이 두번 일어나야 한다는 단점은 있지만, 현재 상황에서 필요한 페이지 프레임의 수가 급격하게 줄어들었다. (모든 주소 공간을 사용하게 되면 오히려 필요한 페이지 프레임이 하나 더 추가되었지만, 요구 페이징때 언급했듯 그렇지 않은 경우가 더 많다.)
위와 같은 2단계 이상 페이징을 할 때, 페이지 테이블을 가리키는 페이지 테이블같은 표현을 사용하기보단, 페이지 디렉토리란 표현을 사용한다.
64비트 적용, 일반화
이제 이전의 32비트 환경에서 64비트 환경으로 확장해보자. 앞서 문제 정의 과정에서도 언급했듯, 주소 공간을 모두 사용하면 그 크기가 너무 과도하기 때문에, 현실적으로는 48비트 주소공간으로 한정한다. (주소 공간을 48비트로 한정한다는 것이지, CPU는 여전히 64비트를 사용하며, 주소 범위도 64비트로 존재할 수 있다.)
32비트에서 확인했던 2단계 페이징과 기본적인 원리는 동일하다. 페이지 테이블의 연속 할당 문제, 불필요한 페이지 테이블을 위한 메모리 할당 등의 문제를 해결하기 위해 2단계 이상의 페이징이 필요하다.

하지만 CPU가 다루는 비트의 개수가 2배가 되면서, 엔트리 표현에 필요한 주소가 2배가 되었다. 현재 페이지 프레임의 크기가 같은데, 주소 표현을 위한 크기가 2배가 됨으로서, 한 페이지 프레임에 표현할 수 있는 엔트리(주소)의 개수가 절반으로 줄어들었다. (32비트에서 1024개 주소를 표현했던 것이 64비트에서 512개가 되었다.)
가상 주소를 비트 단위로 바라보면, 32비트에서는 10비트의 값만 변경되는데, 64비트에서는 9비트만 변경된다. 즉, 64비트에서는 페이징 단계마다 9비트씩 다루면 된다. 이 규칙을 좀 더 일반화해보자.
먼저, 한 페이지 프레임에 몇 개의 엔트리를 표현할 수 있는지 계산하려면, 현재 페이지의 크기를 CPU가 표현 가능한 크기로 나누면 된다. (보통 메모리 주소 공간은 바이트로 표기하고, CPU의 단위는 비트로 표기하므로 이를 통일해야한다.) 한 페이지에서 표현 가능한 엔트리 개수만큼 실제 비트로 표현하려면, log2()를 취하면 그 숫자를 표현하기 위해 필요한 비트의 길이가 나온다.
이 규칙을 응용하면 제일 처음 말했던 -2, -3의 원리를 알 수 있다. 32비트는 4바이트이며, log2(4) == 2다. 64비트는 8바이트이며, log2(8) == 3이다. 페이지의 비트에서 -2, -3은 이것을 의미한다.
64-bits, 4KiB
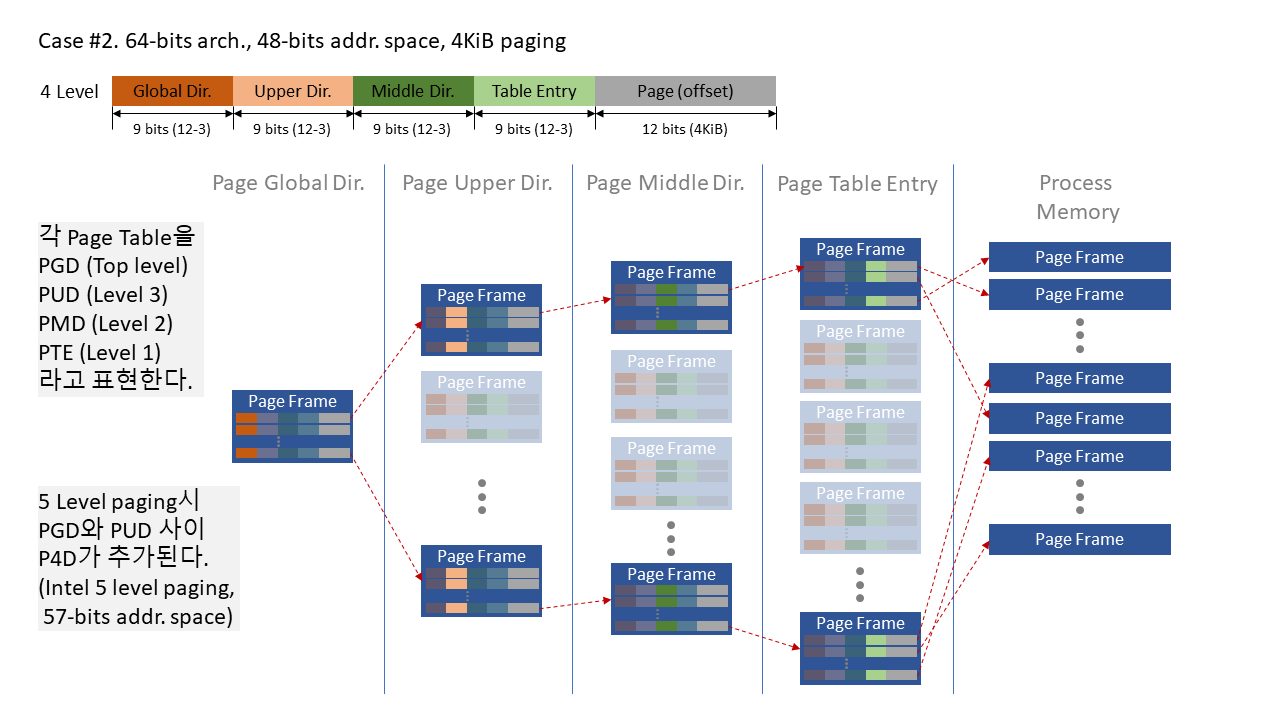
가상 주소 공간의 크기가 커졌기 때문에 페이징 단계가 늘어나는 것은 필연적이다. 실제 프로세스의 주소 공간을 가리키는 엔트리는 그대로 두고, 페이지 디렉토리를 각 단계에 따라 다르게 부른다. 위 그림은 아래쪽으로 갈 수록 레벨 숫자를 낮게 잡았는데, 다른 글에서는 반대로 잡기도 한다. 여기서는 5단계 페이징시 추가되는 p4d의 위치를 고려하여 이렇게 순서를 결정했다.
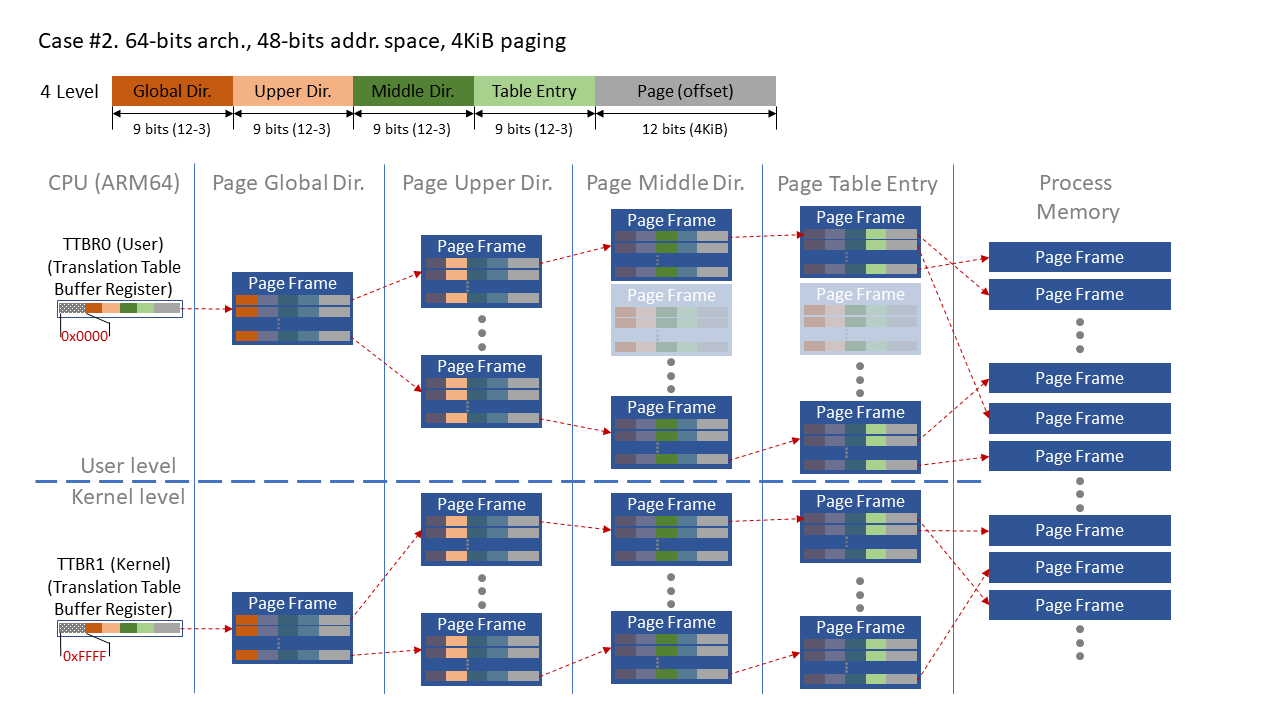
리눅스 커널에서 Intel같은 x86_64의 아키텍쳐에서 관리되는 방법은 모르겠는데, 내가 분석하고 있는 ARM64의 경우 아키텍쳐에서 유저 레벨과 커널 레벨에 대한 페이지 테이블 레지스터를 개별적으로 제공한다. 이 경우 각각 유저 레벨과 커널 레벨이 가리키는 가상주소는 앞의 주소가 달라진다.
기타 이야기
위와 같이 2단계 이상 페이지 테이블에서 원하는 주소의 페이지 프레임 주소를 찾는 과정을 page walk라 한다. 위 1단계 예시 코드를 2단계 이상으로 확장한 코드의 예시는 여기를 참고하자.
페이징 개념을 배울 때는 페이지의 크기를 원하는 대로 설정할 수 있다는 식의 이야기를 하지만, 실무에서는 사용할 수 있는 페이지의 크기 종류는 매우 제한적이다. 그리고 대부분 아키텍쳐에 의존적이다. 리눅스 커널의 설정만 봐도 얼마나 한정적인지 알 수 있을 것이다.